Data Table
Data Table タブはデータセットの内容を表形式で表示し、フィルタやソートでデータを調べられます。
基本的な使い方 もご覧ください。
フィルタ機能
フィルタ式を入力して、条件に合う行だけを表示できます。
基本的な使い方
- Data Table タブ上部のフィルタ入力欄に式を入力
- Enter キーを押すか、入力欄の外をクリック
- 条件に合う行だけが表示される
フィルタ式の書き方
比較演算子
| 演算子 | 意味 | 例 |
|---|---|---|
= |
等しい | species = 'Adelie' |
!= |
等しくない | species != 'Adelie' |
> |
より大きい | age > 30 |
>= |
以上 | age >= 30 |
< |
より小さい | age < 30 |
<= |
以下 | age <= 30 |
パターンマッチ演算子
| 演算子 | 意味 | 例 |
|---|---|---|
LIKE |
パターンに一致(大文字小文字区別) | name LIKE '%田%' |
ILIKE |
パターンに一致(大文字小文字無視) | name ILIKE '%Smith%' |
NOT LIKE |
パターンに一致しない | name NOT LIKE '%test%' |
パターンの書き方:
%は任意の文字列(0文字以上)を表します_は任意の1文字を表します
例:
name LIKE '%田%'- 「田」を含むname LIKE '山%'- 「山」で始まるname LIKE '%郎'- 「郎」で終わるemail LIKE '%@example.com'- @example.com で終わる
論理演算子
| 演算子 | 意味 | 例 |
|---|---|---|
and |
かつ | age > 30 and sex = 'male' |
or |
または | species = 'Adelie' or species = 'Gentoo' |
() |
グループ化 | (age > 30 or salary > 50000) and active = true |
集合・範囲演算子
| 演算子 | 意味 | 例 |
|---|---|---|
IN (...) |
値のリストに含まれる | species IN ('Adelie', 'Chinstrap') |
NOT IN (...) |
値のリストに含まれない | status NOT IN ('deleted', 'archived') |
BETWEEN ... AND ... |
範囲内(両端含む) | age BETWEEN 20 AND 30 |
NOT BETWEEN ... AND ... |
範囲外 | age NOT BETWEEN 20 AND 30 |
否定演算子
| 演算子 | 意味 | 例 |
|---|---|---|
NOT (...) |
条件の否定 | NOT (status = 'deleted') |
NULL判定と真偽値
| 構文 | 意味 | 例 |
|---|---|---|
IS NULL |
欠損値 | bill_length_mm IS NULL |
IS NOT NULL |
欠損値でない | bill_length_mm IS NOT NULL |
true / false |
真偽値 | active = true |
列名にスペースや特殊文字が含まれる場合
列名をダブルクォートで囲みます(DuckDB SQL標準):
"Body Mass (g)" > 4000
フィルタの例
# 数値の条件
body_mass_g > 4000
# 文字列の条件(シングルクォートで囲む)
species = 'Chinstrap'
# 複数条件の組み合わせ
species = 'Adelie' and body_mass_g > 3500
# 欠損値を除外
bill_length_mm IS NOT NULL
# パターンマッチ(部分一致)
island LIKE '%Dream%'
# 複数の値に一致
species IN ('Adelie', 'Gentoo')
# 範囲指定
body_mass_g BETWEEN 3500 AND 4500
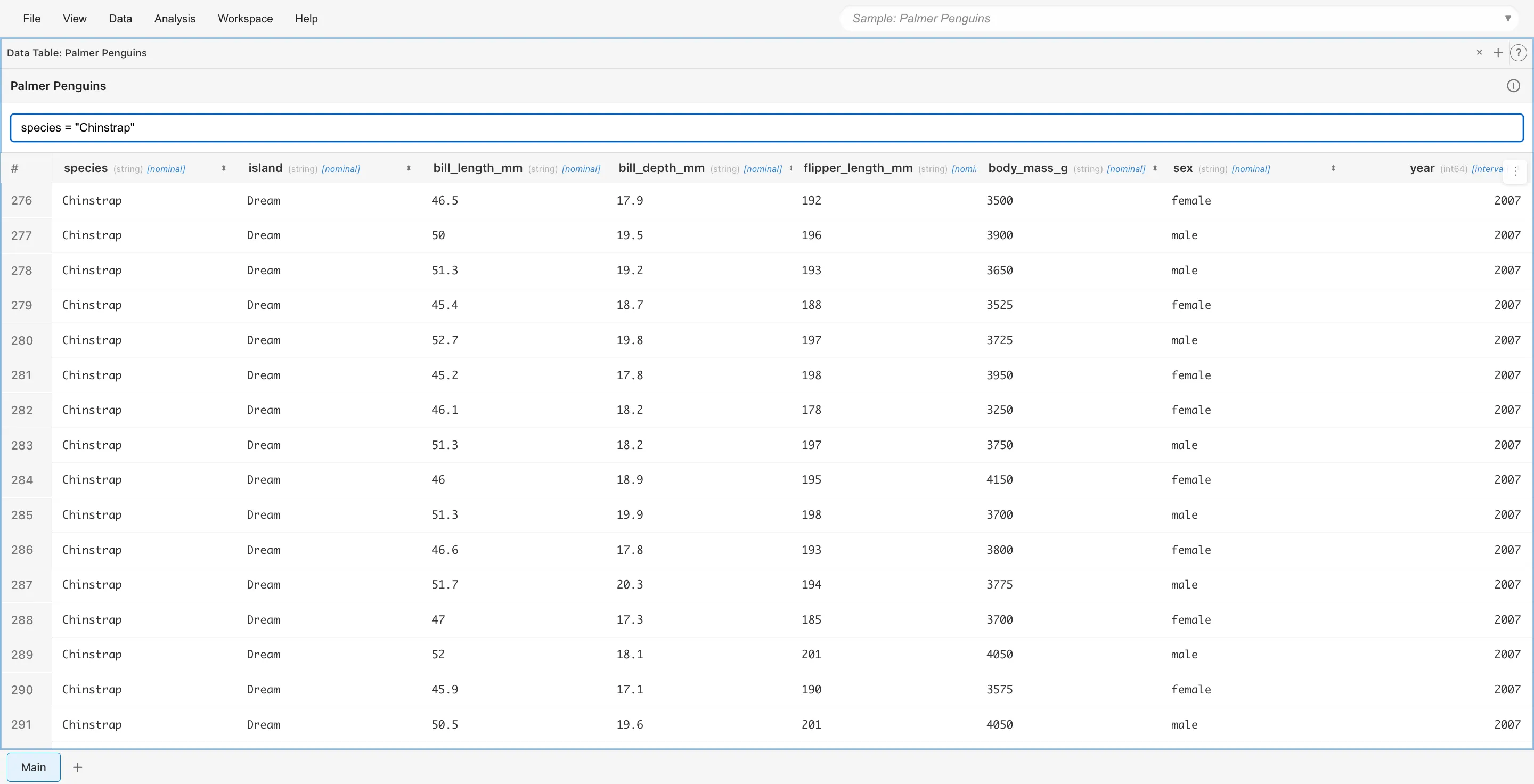
ソート機能
列ヘッダーのソートボタン(⬍)をクリックすると、その列でデータをソートできます。
単一列ソート
- 1回クリック: 昇順(▲)
- 2回クリック: 降順(▼)
- 3回クリック: ソート解除
複数列ソート
Ctrl キー(Mac: Cmd キー)を押しながらクリックすると、複数列でソートできます。
- Ctrl+クリック: ソート条件を追加(昇順)
- 同じ列を再度 Ctrl+クリック: 降順に変更
- さらに同じ列を Ctrl+クリック: その列のソートを解除
複数列ソート時は、ソートボタンに優先順位の番号が表示されます(▲1、▼2 など)。
行の選択
Data Table で行を選択すると、他のタブ(Statistics、Graph Builder など)と選択状態が連動します。
選択方法
- 単一行: 行をクリック
- 範囲選択: Shift キーを押しながらクリック
- 追加選択: Ctrl キー(Mac: Cmd キー)を押しながらクリック
- 選択解除: 選択済みの行をクリック、または空白部分をクリック
他のタブとの連動
Data Table で選択した行は、他のタブと連動します:
- Statistics タブ: 選択した行のみの統計量が表示される(全体との比較に便利)
- Graph Builder: 選択した行がハイライト表示され、特定のデータポイントを視覚的に確認できる
例えば、外れ値と思われる行を選択して Statistics タブで確認したり、特定条件のデータだけをグラフ上で強調したりできます。
データセットメニュー
列ヘッダー右端のメニューボタン(︙)から、以下の操作ができます。
Metadata
データセットの基本情報(データセット名、行数・列数、各列のデータ型と測定尺度)を確認できます。
Convert Column Types
列のデータ型を変換するタブを開きます。詳しくは 列の型変換 をご覧ください。
Reload Dataset
元のCSVファイルからデータを再読み込みします。ファイルを編集した後に変更を反映したい場合に使用します。この機能は Primary データセット(直接読み込んだCSV)でのみ利用可能で、SQL Editor で作成した派生データセットでは表示されません。
View SQL Query
SQL Editor で作成した派生データセットの場合、元のSQLクエリを確認できます。
行番号列
左端の列は行番号を表示します。この行番号は元データの順序を示し、フィルタやソートを適用しても変わりません。
関連ページ
- データの準備と読み込み - データ型と測定尺度について
- SQL Editorによるデータ加工 - SQLでのデータ加工
- 基本統計量 - 選択行の統計量を確認